AllSpark: Reborn Labeled Features from Unlabeled in Transformer for Semi-Supervised Semantic Segmentation
摘要:
目前最先进的方法是用真实标签训练标注数据,用伪标签训练未标注数据。然而,这两个训练流程是分开的,这就使得标注数据在训练过程中占据主导地位,从而导致伪标签的质量低下,并因此产生次优结果。为了缓解这一问题,我们提出了 AllSpark ,它利用信道交叉注意力机制从未标明的特征中重新生成标明的特征。我们进一步引入了语义记忆和通道语义分组策略,以确保未标记的特征充分代表已标记的特征。AllSpark 为 SSSS 的架构级设计而非框架级设计提供了新的思路,从而避免了日益复杂的训练流水线设计。它还可以被视为一个灵活的瓶颈模块,可以无缝集成到基于转换器的通用分割模型中。
介绍:
大多数最先进的 SSSS 方法 [23, 24, 26, 31, 50] 都基于伪标签 [22, 34] 方案,即根据模型预测为未标签数据分配伪标签。然后使用这些伪标签数据对模型进行迭代训练,就像使用已标记的示例一样。根据标注数据和未标注数据的训练流程,目前的先进技术主要可分为两类:(1) 连续式、最有代表性的是以教师和学生为基础的框架[17, 20, 36, 44, 45, 56]。首先用标注数据进行训练,然后用指数移动平均值更新教师模型。(2) 并行,以 CPS(交叉伪监督)为代表[6, 23, 46, 50],即在一个小批量内将已标记数据与未标记数据串联起来,模型通过一致性正则化同时优化这两种数据流。
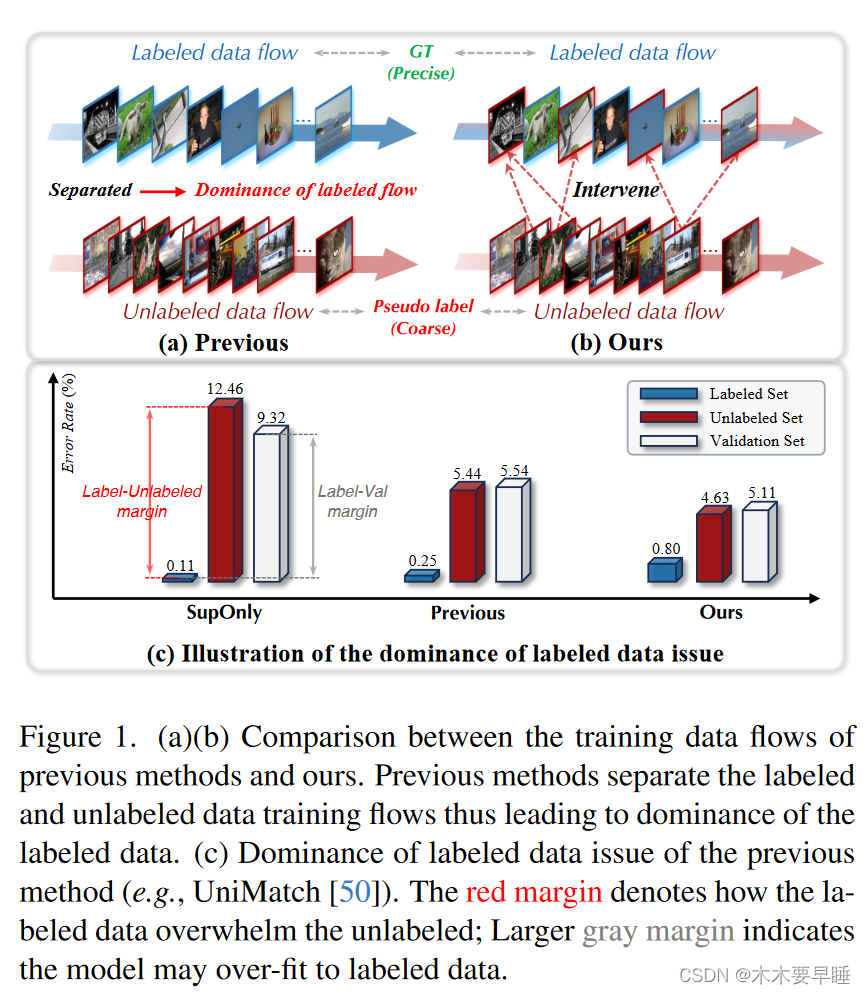
如图 1(a) 所示,这些最先进方法的一个主要特点是将标注数据和非标注数据的训练流程分开。由于标注数据带有标签,因此训练流的分离使得标注数据在训练过程中占据主导地位;见图 1(c)。然而,这些方法都有一个共同的重大缺陷:用于为未标记图像生成伪标签的模型受到有限的标记样本集的严重影响,从而导致伪标签质量低下,结果不尽人意。遗憾的是,以往的研究忽略了这一重要观察结果。
为此,我们提出了一种新颖的方法:我们不直接在已标注样本上进行训练,而是利用未标注样本生成已标注特征(如图 1(b) 所示)。这种方法的基本原理是,已标注数据远远少于未标注数据,通过从未标明数据中重新生成已标注特征,我们在已标注数据流中引入了多样性,从而创造了更具挑战性的学习环境。标注分支不完全依赖自我重构,而是学会从未标明的特征中提取有价值的通道。通道中的通用语义信息为这一想法提供了可行性,例如,如图 3 所示,"船 "的标注样本和 "飞机 "的非标注样本表现出相似的金属材料质地。
接下来的步骤是确定一种有效的方法来重新生成标注数据。幸运的是,最初在变压器解码器中使用的交叉注意机制 [39] 提供了一种合适的方法,因为它旨在利用源序列重建目标序列。因此,我们在交叉注意概念的基础上开发了我们的方法,并将其调整为以信道方式运行[9, 42],以提取信道语义信息。如图 2 所示,这种名为 AllSpark 的方法利用标记数据特征作为q,利用未标记数据特征作为k和v。具体来说,AllSpark 会计算已标注特征的每个通道与未标注特征之间的相似性矩阵。然后强调相似度最高的未标记通道,以重建已标记的特征。然而,实现这一想法的关键挑战在于mini批次中有限的未标注特征,这些特征可能不足以重建正确的标注特征。为了解决这个问题,我们引入了语义内存(Semantic Memory,S-Mem),从以前的未标记特征中收集通道。S-Mem 采用建议的通道语义分组策略进行迭代更新,该策略首先将代表相同语义的通道分组,然后将它们排入 S-Mem 的相应类别插槽。

相关工作:
Semantic Segmentation
略
Semi-supervised Semantic Segmentation
传统的半监督语义分割(SSSS)方法侧重于如何通过框架级设计更好地利用未标记数据,并使用基于 CNNs 的基本分割模型作为骨干。其中最引人注目的两个基本框架是教师-学生(teacherstudent)[20, 36, 44, 45, 56] 和交叉伪监督(CPS)[6, 46, 50]。具体来说,在基于教师学生的框架中,首先用标注数据训练学生模型,然后用学生的指数移动平均(EMA)更新教师模型,生成伪标签。在基于 CPS 的框架中,标注数据与未标注数据在一个迷你批次中串联起来,模型通过一致性正则化同时优化这两种数据流。
最近,有几项研究探索了基于 Transformer 的模型,以扩展 SSSS 的边界。具体来说,SemiCVT [17] 提出了一种模型间的类一致性,以交叉教学的方式补充 CNN 和 Transformer 的类级统计。其他方法[23, 25]在基于 CPS 的框架[6]中利用 ViT 作为 CNN 的多样化模型。这些方法可以概括为基于 CNN-Transformer 的方法,它们利用变换器的方式都很幼稚,因此限制了 ViT 潜力的充分发挥。与这些方法不同,我们通过架构层面的设计为纯变压器 SSSS 方法带来了新的启示。
AllSpark: Reborn Labeled Features from Unlabeled Features
Channel-wise Cross-attention: the Core of AllSpark

为了缓解单独训练方案带来的有偏差的标注数据的主导地位,我们提出了 AllSpark 方案,用非标注数据直接介入标注数据训练流程。通常,不同的特征通道编码不同的语义信息。与补丁标记相比,这些通道特征包含更丰富的上下文信息,在各种输入图像中更具通用性(参见图 7)。我们利用这些来自未标记数据的上下文信息,使用通道交叉关注机制(channelwise crossattention mechanism)[9, 42]重建标记数据的特征,作为一种稳健的正则化。在这一机制中,有标签的数据特征作为q,而无标签的特征作为k和v,如图 3 所示。具体来说,我们计算已标注特征的每个通道与未标注特征之间的相似度,相似度最高的未标注通道在重构已标注特征时发挥更重要的作用。其基本原理是,即使与已标记的特征相比,未标记的特征可能来自不同的类别,但它们仍然拥有可以共享的具有通道智慧的通用信息,例如纹理。

在编码器阶段后,给定已标记数据和未标记数据的隐藏特征 [hl, hu],我们将其拆分,然后以多头方式将 hl 设置为q,hu 设置为k和v:

其中,wq、wk、wv∈R C×2C 为变换权重,hl、hu∈R C×d,d 为序列长度(斑块数),C 为信道维度。通道关注度定义如下 :
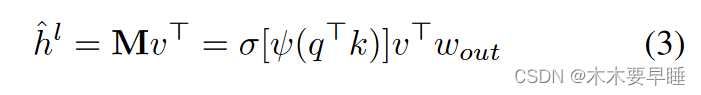
其中,ψ(-)和σ(-)分别表示实例归一化[37]和软最大函数,wout∈R2C×C。与传统的自我关注机制相比,信道明智的自注意可以捕捉通道之间的长距离依赖关系。为了进一步完善未标注数据的隐藏特征,我们还应用了通道自注意力。获得细化的未标记特征 ˆ h u i 的公式与公式 2 和 3 类似,唯一不同的是 q 被替换为 q = hu wq。重建的 ˆ hl i 和 ˆ hu i 随后被输入解码器,生成最终预测结果。
Semantic Memory for Enlarging the Feature Space of AllSpark
在单个mini批次中直接利用未标记的特征不足以有效地重生已标记的特征。为了克服这一限制,我们需要扩展 未标记的特征空间。为此,我们引入了一个先进先出队列--分类语义内存(SMem),用于存储大量未标记的特征,如图 4 底部所示。该内存允许我们在重建过程中有效地访问更广泛的未标记特征。

S-Mem 的形状为 R K×C×d,其中 K 代表类别数。对于每个类别,S-Mem 存储 C 个通道,每个通道由 d 个贴片组成。在训练过程中,我们利用语义记忆替换未标记特征的原始k和v分量(公式 3 中的 kT 和 vT)。在下一小节 §3.4 中,我们将演示如何用包含特定类别语义信息的精确通道更新每个类别槽。
Channel-wise Semantic Grouping
以天真的方式存储之前未标记的特征并不适合语义分割任务,因为类别往往是不平衡的。为了确保每个类别都有足够的语义信息,有必要建立一个类别平衡的语义记忆。因此,我们引入了通道语义分组(Channel-wise Semantic Grouping)策略,以确定未标记特征中每个通道的语义表示,然后将它们分组并添加到 SMem 的相应类槽中,如图 4 所示。具体来说,我们计算未标记特征 hu∈ RC×d 与概率标记 ˆ p∈ RK×d 之间的相似度。概率标记是从概率图 p∈RK×H×W 中得到的经过调整和重塑的向量,它是分割网络的软预测,包含 hu 的整体语义信息。确定每个通道的语义表示后,我们就可以根据各自的语义类别将它们存储在存储器中。相似性矩阵 Sim ∈ RK×C 的定义为Simi,j = ψ(ˆ p⊤ j hu i )。这样,通过比较第 i 个(i∈[0, C])通道的语义信息和图像的整体语义上下文,我们就能确定第 i 个通道最有可能代表的语义类别。然后,我们将代表相同语义类别的通道分组,并将它们排入语义存储器中相应的类别槽。
在推理阶段,虽然我们仍然可以利用 S-Mem 的交叉注意机制,但它往往会带来计算负担,而且对性能的改善微乎其微。为了提高效率,我们选择在推理阶段取消 S-Mem 和 CSG。因此,交叉注意的两个输入变得相同,可以简化为自我注意。